
Tra J.A.R.V.I.S. e Jeeves
Tutto quanto c'è da sapere per creare un assistente AI ovvero linee guida comparative intorno a GPT personalizzati, Google Gems e Claude Projects.

⏱ Tempo di lettura stimato: 15 minuti
«Ho più ricordi io da solo di quanti ne avranno avuti tutti gli uomini da quando il mondo è mondo.»
— Jorge Luis Borges, Funes, o della memoria, in Finzioni, trad. it. Franco Lucentini, Einaudi, Torino, 1955 (ed. orig. Funes el memorioso, in Ficciones, 1944).
Maggiordomi smemorati
J.A.R.V.I.S., l’intelligenza artificiale che gestisce la vita di Tony Stark con discrezione sovrumana, e Jeeves, il maggiordomo letterario di P.G. Wodehouse, che risolve ogni catastrofe senza mai alzare un sopracciglio sono due archetipi dell’assistente perfetto e ciò che li accomuna è il possesso di un contesto inesauribile sul proprio interlocutore: sanno chi è, cosa vuole, cos’ha combinato la settimana scorsa e perché (non) ha voglia di rifarlo.
I modelli linguistici che usiamo quotidianamente come ChatGPT, Gemini e Claude sono ormai molto affidabili, ma soffrono di un’amnesia strutturale che li rende l’esatto opposto di Jeeves. Ogni nuova conversazione è per loro la prima: non ricordano il tuo nome, le tue preferenze, i tuoi documenti. Come avere a disposizione un consulente brillantissimo o un maggiordomo molto sollecito che però, a ogni incontro, si presenta come fosse la prima volta.

I GPT personalizzati, i Google Gems e i Claude Projects nascono per risolvere questo problema. Ma prima di esplorare come funzionano, è necessario puntualizzare tre concetti che il marketing confonde con entusiasmo colpevole.
Avvertenza. Le informazioni contenute in questo articolo sono aggiornate a marzo 2026. Il settore evolve a velocità che rendono obsoleto qualsiasi testo nel giro di pochi giorni. Vi raccomando di verificare la documentazione ufficiale delle rispettive piattaforme prima di prendere una qualsiasi decisione operativa.
Assistenti, agenti e copiloti: tre cose molto diverse
Un assistente AI è un sistema reattivo. Risponde a richieste esplicite: riceve un input, produce un output, si ferma. Non prende iniziative, non esegue azioni nel mondo se non interrogato. I GPT personalizzati, i Gems e i Projects appartengono a questa categoria. Jeeves, per quanto onnisciente, non agisce mai senza che Bertie Wooster glielo chieda.

Un agente AI è un sistema capace di azione autonoma orientata a un obiettivo. Riceve un compito di alto livello e lo scompone in sotto-compiti, decide quali strumenti utilizzare, esegue azioni nel mondo (chiamare un’API1, navigare un sito, interrogare un database), verifica i risultati e corregge la rotta senza intervento umano continuo. Qui siamo più vicini a J.A.R.V.I.S. Strumenti come Claude Code, Codex di OpenAI o i Deep Research agents di Google operano in questa modalità.

Un copilota occupa una posizione intermedia: lavora fianco a fianco con l’utente in un ambiente specifico, suggerendo completamenti e correzioni in tempo reale, ma senza mai sostituirsi all’operatore. È il compagno di banco sveglio che ti passa il suggerimento, non il prof da cui vai a ripetizione che ti fa trovare i compiti fatti.

Chi ha bisogno di automazione, come flussi multi-step con logica condizionale, non troverà risposta negli assistenti personalizzati di cui parliamo qui. Se è quello che state cercando, lasciate perdere questo articolo e cominciate a studiare n8n.
Il problema che tutti e tre cercano di risolvere
Il Funes di Borges ricordava ogni foglia di ogni albero — e la sua condanna era proprio questa: un eccesso di dati senza gerarchia, senza astrazione. I LLM soffrono del problema opposto: una capacità di ragionamento notevole, ma un’amnesia radicale. Per un uso occasionale, la cosa è irrilevante. Per chi lavora con questi strumenti quotidianamente, la ripetizione ha costi cognitivi temporali non trascurabili.
Le tre piattaforme principali, Anthropic, Google e OpenAI2 , hanno affrontato la questione con approcci diversi ma convergenti sull’obiettivo di fornire un modo per creare assistenti dotati di contesto persistente, senza scrivere codice. Le implementazioni differiscono per filosofia progettuale, capacità tecniche e modello di distribuzione.
GPT personalizzati: l’ecosistema di OpenAI
OpenAI ha introdotto i GPT personalizzati alla fine del 2023. Un GPT personalizzato è una versione specializzata di ChatGPT che opera secondo istruzioni definite dall’utente e può attingere a una base documentale dedicata.
Il panorama dei modelli sottostanti si è rinnovato profondamente: a febbraio 2026 sono stati ritirati GPT-4o, GPT-4.1, GPT-4.1 mini, o4-mini e GPT-5 (Instant e Thinking). I modelli attualmente in uso vanno da GPT-5.2 al recentissimo GPT-5.4, rilasciato il 5 marzo 2026, che unifica la linea Codex con quella GPT principale e introduce capacità native di computer use. I creatori di GPT personalizzati possono scegliere tra l’intera gamma disponibile e impostare un modello raccomandato per gli utenti.
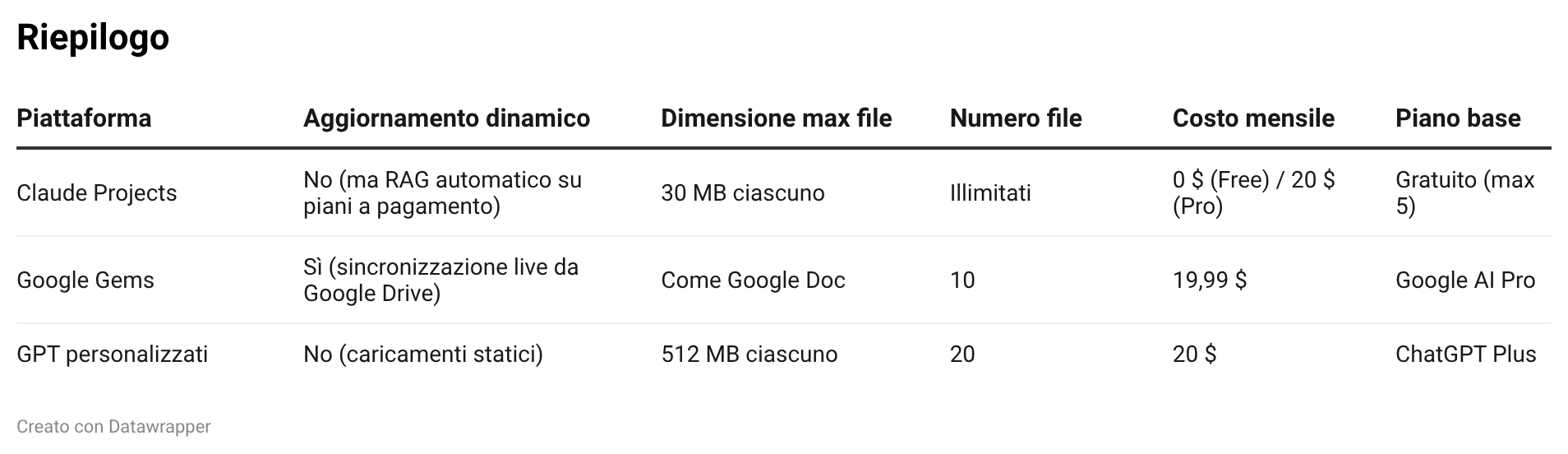
I quattro pilastri della configurazione. Un GPT personalizzato poggia su: azioni personalizzate (Custom Actions) per collegare API esterne; capacità attivabili (analisi dati, code interpreter3, generazione immagini, navigazione web, modalità vocale); file di conoscenza (fino a 20 file, ciascuno fino a 512 MB, ma statici, non si aggiornano se la fonte cambia); istruzioni di sistema che stabiliscono ruolo, competenze, tono e vincoli comportamentali4.
Distribuzione. Il GPT Store resta l’elemento senza equivalenti: un marketplace dove chiunque abbia ChatGPT può scoprire e utilizzare GPT creati da altri. Tre livelli di accesso: privato, condiviso tramite link, pubblico. È l’unica piattaforma tra le tre a offrire un canale di distribuzione aperto.
Costi. I piani ChatGPT nel 2026: Free, Go (8 $/mese), Plus (20 $/mese), Pro (200 $/mese). Secondo la documentazione ufficiale sulla creazione dei GPT, l’accesso al GPT Builder è riservato ai piani Plus, Pro, Business, Enterprise ed Edu. Il piano Go include l’uso di GPT personalizzati già esistenti e la possibilità di creare Custom GPTs, ma la documentazione OpenAI presenta informazioni non del tutto coerenti tra le diverse pagine di supporto.
In arrivo: il sistema Skills. OpenAI sta testando internamente un sistema chiamato Skills (nome in codice “Hazelnut”), che punta a sostituire i GPT basati su ruoli con abilità modulari: competenze discrete, combinabili dinamicamente, che si caricano solo quando necessario. Si tratta di informazioni provenienti da fonti non ufficiali; OpenAI non ha rilasciato alcuna documentazione in merito.
Google Gems: l’assistente che vive nel tuo studio
Google ha lanciato i Gems nell’agosto 2024 come funzionalità di Gemini. Da allora il contenitore commerciale è cambiato, ma la sostanza dei Gems è rimasta la medesima.
Dove i Gems si distinguono. Finestra di contesto5: un milione di token6, equivalenti a circa 1.500 pagine di testo. Gems sperimentali e Super Gems (2026): mini-app AI personalizzate per compiti quotidiani, con moduli e pulsanti interattivi. Integrazione live con Google Drive: a differenza dei GPT personalizzati (dove i file caricati sono istantanee congelate), i Gems si collegano direttamente a Google Docs: quando aggiorni il documento, il Gem vede immediatamente la modifica.
L’ecosistema Workspace. Il pannello laterale Gemini e le funzionalità inline sono disponibili in Chat, Docs, Drive, Meet, Sheets e Slides. Per chi vive già in questo ecosistema, l’adozione è un’estensione naturale delle abitudini esistenti.
Costi. I Gems sono inclusi nel piano Google AI Pro (19,99 $/mese). Esiste anche un livello superiore, Google AI Ultra (circa 42 $/mese, venduto a trimestri), con limiti più alti e accesso a modelli avanzati. La funzionalità base è accessibile anche agli utenti del piano gratuito, con le prevedibili limitazioni.
Claude Projects: lo studio del ricercatore
Anthropic ha fatto una scelta diversa. Anziché creare assistenti da distribuire in un marketplace, i Projects sono spazi di lavoro persistenti: stanze, quasi nel senso fisico del termine, in cui Claude mantiene il contesto attraverso conversazioni multiple.
Anatomia di un Project. Ogni Project contiene: istruzioni personalizzate (competenze di dominio, formato, tono, vincoli); libreria documentale (fino a 30 MB per file, senza limite al numero di file, nei formati CSV, DOCX, HTML, PDF, TXT e altri); cronologia delle conversazioni (tutte le chat restano collegate, ma il contesto non si condivide automaticamente tra chat diverse a meno che le informazioni siano nella knowledge base comune); collaborazione (nei piani Enterprise e Team, con permessi granulari).
Claude è particolarmente forte nella comprensione e sintesi di documenti lunghi e complessi. Nei piani a pagamento, quando la conoscenza del progetto si avvicina ai limiti del contesto, Claude attiva automaticamente la modalità RAG7 per espandere la capacità fino a dieci volte.
Lo stato dell’arte tecnologico. Claude Opus 4.6, rilasciato il 5 febbraio 2026, porta la finestra di contesto a 1 milione di token con miglioramenti nel coding, nella pianificazione e nell’analisi. Claude Sonnet 4.6 è seguito il 17 febbraio con consumi di token ridotti.
Costi. I Projects sono disponibili per tutti gli utenti, compresi quelli gratuiti (massimo 5 progetti). Il piano Pro a 20 $/mese offre progetti illimitati con RAG automatico. Claude Max (100 $/mese per la versione 5x, 200 $/mese per la 20x) moltiplica i limiti di messaggi.
Confronto diretto
Chi vede cosa: privacy, dati e addestramento
Questo è il tema che la maggior parte delle guide comparativa sorvola, ma che per un uso professionale è tra i più importanti. Chi carica documenti di lavoro in un assistente AI deve sapere con chiarezza che fine fanno quei dati.
Anthropic. Dal settembre 2025, Anthropic ha introdotto un modello opt-in per l’addestramento sui piani consumer (Free, Pro, Max). L’utente viene invitato a scegliere tramite un toggle (”You can help improve Claude”): chi accetta consente la conservazione dei dati in forma de-identificata fino a 5 anni; chi rifiuta mantiene la retention a 30 giorni. Le conversazioni eliminate non vengono mai utilizzate per l’addestramento. I piani Enterprise e API (incluso l’accesso tramite Amazon Bedrock e Google Cloud Vertex AI) restano esclusi dall’addestramento. Zero Data Retention (ZDR) è disponibile solo per i piani Enterprise. I dati nei Projects seguono le stesse regole del piano sottoscritto.
Google. La situazione è stratificata. Sull’app Gemini gratuita, le conversazioni possono essere riviste da revisori umani e utilizzate per migliorare i servizi. Google lo dichiara esplicitamente nella Gemini Apps Privacy Notice, consigliando di non inserire informazioni che non si vorrebbe fossero viste da un revisore. Per gli utenti Google Workspace (Business, Enterprise, Education), le regole cambiano radicalmente: i dati sono considerati “customer data” ai sensi del Cloud Data Processing Addendum e non vengono utilizzati per addestrare i modelli al di fuori del dominio dell’organizzazione senza consenso esplicito. I Gems creati tramite Google Labs (la variante sperimentale) seguono regole a parte: i dati associati sono gestiti secondo la Google Privacy Policy generale, non secondo la Gemini Apps Privacy Notice.
OpenAI. Sui piani consumer (Free, Go, Plus, Pro), le conversazioni con i GPT personalizzati possono essere utilizzate per addestrare i modelli. L’impostazione è attiva per default — l’utente deve disattivarla manualmente (Impostazioni → Data Controls → “Improve model for everyone”). La modalità Temporary Chat esclude la conversazione dall’addestramento e dalla cronologia, ma va attivata ogni volta. Sui piani Business ed Enterprise, l’addestramento sui dati degli utenti è disabilitato per default. I dati vengono conservati fino a 30 giorni per monitoraggio abusi anche dopo l’opt-out. Attenzione: se un GPT personalizzato utilizza Custom Actions collegate ad API esterne, parti dell’input possono essere inviate a servizi terzi che OpenAI non controlla.
In sintesi. Nessuna delle tre piattaforme, sui piani consumer, garantisce per default che i dati non vengano utilizzati per l’addestramento. Tutte e tre richiedono un’azione esplicita dell’utente per escludersi. Per un uso professionale con dati sensibili, i piani Enterprise o Business di ciascuna piattaforma sono l’unica opzione ragionevole — e anche in quel caso, la verifica delle condizioni contrattuali specifiche resta indispensabile.
L’arte di istruire una macchina (senza annoiarla)
Alcune impostazioni valgono indipendentemente dalla piattaforma scelta.
Curatela della base documentale. Non serve caricare tutto. La qualità del contesto dipende dalla pertinenza dei documenti rispetto al compito, non dalla quantità. Un eccesso di documenti irrilevanti degrada le risposte. Serve una cadenza di revisione periodica e la disciplina di rimuovere i contenuti obsoleti.
Specificità, non verbosità. Istruzioni di migliaia di parole possono disorientare il modello: occupano contesto e introducono potenziali contraddizioni. Meglio poche direttive chiare e strutturate: dichiarazione del ruolo, formato della risposta, vincoli espliciti su ciò che il modello non deve fare. Come osservava Blaise Pascal in tutt’altro contesto, «non ho avuto il tempo di scrivere una lettera breve».
Test dei casi limite. Prima di usare un assistente in produzione, è saggio testare scenari imprevisti: domande fuori ambito, input ambigui o contraddittori. Un assistente ben costruito gestisce l’imprevisto con trasparenza, dichiarando i propri limiti anziché confabulare o allucinare. Meglio un «non posso rispondere con i documenti disponibili» che un’invenzione spacciata per un fatto.
Prompt di avvio. Tutte e tre le piattaforme consentono di definire suggerimenti di avvio conversazione. Non è un dettaglio cosmetico: prompt ben costruiti guidano l’utente verso i punti di forza dell’assistente. Un’istruzione di sistema che sia efficace per tutte e tre le piattaforme ha una struttura comune basata sulla dichiarazione di ruolo e contesto; regole esplicite di comportamento (incluso ciò che il modello non deve fare); formato della risposta atteso; suggerimenti di avvio. Ecco un esempio:
Sei un tutor di programmazione Python per studenti universitari al primo
anno. Non hanno esperienza pregressa di coding.
Regole pedagogiche:
- Spiega sempre il ragionamento PRIMA di mostrare il codice
- Usa analogie con la vita quotidiana per i concetti astratti
- Ogni blocco di codice deve avere commenti riga per riga
- Se lo studente fa un errore, non dare la soluzione: guida con
domande socratiche
- Rispetta rigorosamente PEP 8
- Non usare librerie esterne nelle prime 10 conversazioni
Struttura della risposta:
1. Concetto in linguaggio naturale (2-3 paragrafi)
2. Esempio di codice commentato
3. Esercizio proposto (con difficoltà crescente)
4. Domanda di verifica per lo studente
A chi serve cosa
Chi vive in Google Workspace → Gems. La sincronizzazione live con Drive, il pannello laterale in Docs e Sheets, e l’integrazione profonda con l’intero ecosistema Google rendono i Gems la scelta a frizione zero.
Chi ha bisogno di integrazioni API o distribuzione pubblica → GPT personalizzati. Le Custom Actions e il GPT Store non hanno equivalenti. Per chi vuole costruire assistenti che devono essere accessibili a un pubblico ampio, OpenAI offre l’infrastruttura più semplice.
Chi lavora con documenti complessi su progetti a lungo termine → Claude Projects. L’assenza di limiti sul numero di file, il RAG automatico, la cronologia persistente e la capacità di analisi su documenti lunghi rendono Claude la scelta naturale per analisti, ricercatori, scrittori e sviluppatori impegnati in lavori iterativi.
Nessuna delle tre opzioni richiede competenze di programmazione. Istruzioni chiare, documenti pertinenti e una fase di test adeguata sono sufficienti per costruire un assistente che, se non proprio come Jeeves, almeno non ti chieda chi sei ogni mattina.
La madre di tutte le domande
Prof, lei cosa usa? Per il momento, 80% Google Gemini Gems e 20% Anthropic Claude Projects. In futuro, le percentuali potrebbero tendere ad allinearsi, mentre resterà piuttosto improbabile che nelle mie macchine si metta a girare un prodotto OpenAI.
Sitografia
9to5Google, “What Gemini Features You Get with Google AI Plus, Pro & Ultra [February 2026]”. https://9to5google.com/2026/02/21/google-ai-pro-ultra-features/ (consultato: 7 marzo 2026).
Anthropic, “Claude Opus 4.6”. https://www.anthropic.com/news/claude-opus-4-6 (consultato: 7 marzo 2026).
Anthropic, “Claude Developer Platform – Release Notes”. https://platform.claude.com/docs/en/release-notes/overview (consultato: 7 marzo 2026).
Anthropic, “How Do You Use Personal Data in Model Training?”. https://privacy.claude.com/en/articles/10023555-how-do-you-use-personal-data-in-model-training (consultato: 7 marzo 2026).
Anthropic, “How Long Do You Store My Data?”. https://privacy.claude.com/en/articles/10023548-how-long-do-you-store-my-data (consultato: 7 marzo 2026).
Claude Help Center, “How Can I Create and Manage Projects?”. https://support.claude.com/en/articles/9519177-how-can-i-create-and-manage-projects (consultato: 7 marzo 2026).
Claude Help Center, “What Are Projects?”. https://support.claude.com/en/articles/9517075-what-are-projects (consultato: 7 marzo 2026).
Digital Watch Observatory, “ChatGPT May Move Beyond GPTs as OpenAI Develops New Skills Feature”, 25 dicembre 2025. https://dig.watch/updates/chatgpt-may-move-beyond-gpts-as-openai-develops-new-skills-feature (consultato: 7 marzo 2026).
Google, “Gemini Apps Privacy Hub”. https://support.google.com/gemini/answer/13594961 (consultato: 7 marzo 2026).
Google, “Gemini Apps’ Release Updates & Improvements”. https://gemini.google/release-notes/ (consultato: 7 marzo 2026).
Google, “Generative AI in Google Workspace Privacy Hub”. https://support.google.com/a/answer/15706919 (consultato: 7 marzo 2026).
Google, “Get Started with Gems in Gemini Apps – Gemini Apps Help”. https://support.google.com/gemini/answer/15236321 (consultato: 7 marzo 2026).
Google Workspace Blog, “New Features in Gemini to Deepen Usage for Organizations”, 13 novembre 2024. https://workspace.google.com/blog/product-announcements/new-gemini-gems-deeper-knowledge-and-business-context (consultato: 7 marzo 2026).
OpenAI, “ChatGPT Plans – Pricing”. https://openai.com/chatgpt/pricing/ (consultato: 7 marzo 2026).
OpenAI, “ChatGPT Release Notes”. https://help.openai.com/en/articles/6825453-chatgpt-release-notes (consultato: 7 marzo 2026).
OpenAI, “GPTs Data Privacy FAQ”. https://help.openai.com/en/articles/8554402-gpts-data-privacy-faq (consultato: 7 marzo 2026).
OpenAI, “How Your Data Is Used to Improve Model Performance”. https://help.openai.com/en/articles/5722486-how-your-data-is-used-to-improve-model-performance (consultato: 7 marzo 2026).
OpenAI, “Introducing GPT-5.4”. https://openai.com/index/introducing-gpt-5-4/ (consultato: 7 marzo 2026).
OpenAI, “Model Release Notes”. https://help.openai.com/en/articles/9624314-model-release-notes (consultato: 7 marzo 2026).
OpenAI, “Retiring GPT-4o, GPT-4.1, GPT-4.1 mini, and OpenAI o4-mini in ChatGPT”. https://openai.com/index/retiring-gpt-4o-and-older-models/ (consultato: 7 marzo 2026).
XDA Developers, “Here’s Everything Google Added to Gemini in January 2026”, 1 febbraio 2026. https://www.xda-developers.com/everything-google-added-to-gemini-january-2026/ (consultato: 7 marzo 2026).
API (Application Programming Interface): interfaccia software che consente a due programmi di comunicare secondo regole predefinite. In questo contesto, le API permettono a un assistente AI di inviare richieste e ricevere dati da servizi esterni.
In ordine alfabetico, non gerarchico. Non ho preferenze azionarie da dichiarare.
Code interpreter: funzionalità che consente al modello di scrivere ed eseguire codice in un ambiente protetto, per calcoli, analisi dati e generazione di grafici.
System prompt: istruzione iniziale, invisibile all’utente finale, che definisce il comportamento del modello per l’intera conversazione. A differenza dei messaggi dell’utente, il system prompt è fisso e viene elaborato prima di ogni scambio.
Finestra di contesto (context window): la quantità massima di testo — misurata in token — che un modello può elaborare in una singola interazione. Include input dell’utente, istruzioni di sistema e risposta del modello.
Token: l’unità minima di testo elaborata da un LLM. In media, per l’inglese, un token equivale a circa ¾ di parola; per l’italiano il rapporto è leggermente meno favorevole: un milione di token corrisponde a circa 750.000 parole inglesi.
RAG (Retrieval Augmented Generation): tecnica che combina il recupero di informazioni da una base documentale con la generazione di testo. Riduce le confabulazioni e ancora le risposte a fonti specifiche.